בפוסט הזה נסקור מימוש של מודלי שפה גדולים (LLMs) לניתוח שיחות משקיעים (Earnings Calls) שפותח בחברת S&P Global Research ובהמשך נעבור מהלכה למעשה ונצלול לטכניקה שבליבת התהליך.
הסופר והפילוסוף הצרפתי וולטר טען שהשפה חשובה גם כיוון שהיא עוזרת לנו להסתיר את מחשבותינו. בשונה מהמספרים והעובדות המוחלטות שאנליסטים ומשקיעים מנתחים לעיפה, לאופן התקשורת ומידת השקיפות של מנהלים בכירים בנוגע לאתגרים עסקיים וסוגיות בעייתיות ניתן לרוב משקל דל, אם בכלל, בתהליך הניתוח של חברות, לאו דווקא מפאת חוסר חשיבות.
חברות בורסאיות גדולות נוהגות לקיים שיחת משקיעים בסמוך למועד פרסום הדו״חות הכספיים על אף שאינן מחויבות לכך רגולטורית.
שיחת המשקיעים היא אירוע תקשורתי שמקיימת חברה ציבורית עם משקיעים קיימים ופוטנציאליים, אנליסטים וגורמים פיננסיים נוספים. מטרת השיחה היא לספק מידע שקוף ומקיף על ביצועי החברה, אסטרטגיה עסקית, תחזיות ונושאים רלוונטיים נוספים. רוב השיחות מתנהלות כשיחת וידאו וספקי מידע פיננסי שונים מאפשרים גישה לארכיון של הקלטות ותמלולים. בחלק הראשון של השיחה המנכ״ל.ית וצוות הניהול הבכיר סוקרים נושאים מרכזיים בפעילות העסקית ובתוצאות הכספיות ובחלק השני עונים על שאלות מצד האנליסטים.
הדואט הזה בין ההנהלה והאנליסטים טומן בחובו מידע רב ערך למשקיעים, הן בשאלות והן בתשובות. לפי תוצאות מחקר [1] של חברת S&P, כאשר שאלות האנליסטים קשורות לנושאים שלא נכללו בדברי ההנלה בפתח השיחה ו/או, כאשר התשובה מתחמקמת מלעסוק באופן ישיר בנושא הנשאל, תוחלת התשואה החזויה יורדת. מהצד השני, תקשורת שקופה ומענה ענייני מצד ההנהלה מאפיינים ניהול תקין והגון שבתורם מביאים לתשואות עודפות.
במאמר מוצגות כמה דוגמאות שממחישות היטב את התזה של החוקרים, הבולטת שבהן היא שיחת המשקיעים של חברת האנרגיה אנרון שהתקיימה בסמוך לפרסום הדו״ח הכספי לרבעון השני של שנת 2001. בשיחה אנליסט מבנק גולדמן זאקס שאל את המנכ״ל את השאלה הבאה בקשר להפחתות בגין ירידת ערך שביצעה החברה: ״כמה אנו יכולים להיות בטוחים שאלו יהיו ההפחתות האחרונות?״. המנכ״ל השיב ״אם היינו חושבים שיש מקום להפחתות נוספות בשווי הנכסים, הן היו נכללות בדו״ח הנוכחי. אבל יש לנו לפחות שלושה אזורי אי-ודאות בעסק, כמו שאתם יודעים. כמובן, אזור אחד הוא קליפורניה… יש את הודו… ואחריה כמובן, לסיום תחום הפס-רחב.״
המונח ״הפחתות בגין ירידת ערך״ (Impairment Write Downs) לא נכלל בשום צורה בדברי הפתיח של ההנלה אבל כן הוזכר בשש מהשאלות ששאלו האנליסטים. תשובת המנכ״ל וגם התשובות האחרות לא שידרו ביטחון בלשון המעטה ונראו כמו תמרון התחמקות לא מוצלח. כחודש וחצי לאחר השיחה החברה הגישה מסמכי צ׳פטר 11 (פשיטת רגל) וכמה מחברי צוות ההנהלה נתבעו ע״י רשות ני״ע האמריקאית (SEC) על הונאה חשבונאית.
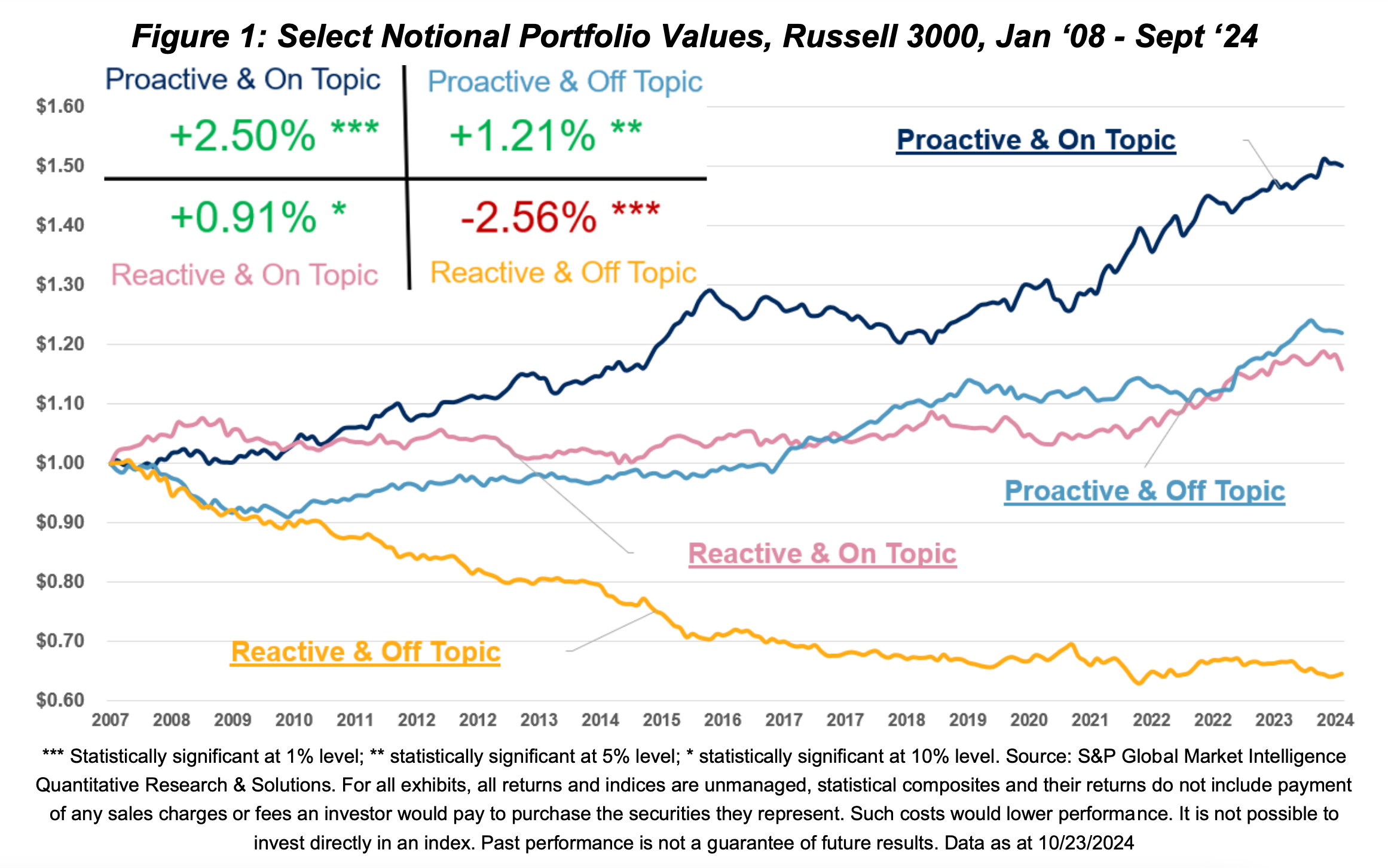
דוגמאות נוספות שהובאו במאמר מראות איך העקרון עובד גם הפוך, כלומר לחיוב, כאשר שקיפות וענייניות נותנים ביטחון למשקיעים, מורידים את הסיכון הגלום בהשקעה בחברה, ובאופן מצטבר מביאים לתשואות עודפות. כמה עודפות? בגרף מטה מתואר הערך הכספי המצטבר בתקופה שמינואר 2008 עד ספטמבר 2024 של ארבע תיקי השקעה (פורטפוליוס) שנבחרו מתוך מדד מניות הראסל 3000 על בסיס הפקטורים הבאים:
בסוף כל חודש קלנדרי במהלך תקופת המבחן ההיסטורי (בקטסט), כל המניות במדד חולקו לתיקי השקעה עפ״י שני הפקטורים הנ״ל כאשר תיק הלונג (חשיפה חיובית) מורכב מהסל הכולל את שני העשירונים עליונים, תיק השורט (חשיפה שלילית) מורכב מהסל הכולל את שני עשירונים התחתונים ויתר החברות (60%) בחשיפה נייטרלית. החיבור של שני הפקטורים הנ״ל בלבד יוצר פער תשואות (אלפא) מרשים בין תיק הלונג והשורט של 506 נקודות בסיס במונחים שנתיים.
מבחן היסטורי (בקטסט) של תיקים שנבחרו על בסיס הפקטורים במחקר. מקור: [1]
רק כדי לוודא שכולנו על אותו דף, כשמדברים על פקטורים בעולם של חיזוי תשואות של תיקי מניות מתייחסים למשתנים מסבירים - כלומר משתנים מדידים כגון שווי שוק, מכפיל הון ומומנטום - שהוכחו כקורלטיביים לתשואה הצפויה. זהו למעשה שדרוג של המודל הקלאסי של מרקוביץ׳ שגרס שהתשואה בהשקעה במניה תלויה באופן ישיר ומוחלט בסיכון הגלום בה שנמדד באמצעות סטיית תקן ומחושב ביחס לשוק כולו. מאז המחקר פורץ הדרך של פמה ופרנץ׳ [2] שהציג את הפקטורים הראשונים בתחילת שנות ה-90 נוספו מאות פקטורים מעבר לסיכון ביחס לתיק השוק כמו גם מחקרים שהציעו שיטות סטטיסטיות להשוואה, סיווג ודירוג של שפע הפקטורים [3].
בחזרה לפקטורים שהוצגו במחקר, באופן מרשים לא פחות מיכולות החיזוי של הפקטורים הנ״ל כאשר הם עומדים בפני עצמם, יכולת החיזוי הגבוהה נשמרת גם בשילוב עם פקטורים אחרים מבוססי עיבוד שפה טבעית (NLP) כמו סנטימנט חיובי ובקיאות מספרית. התובנה הזאת מחזקת את ההנחה הרווחת לפיה מודלי שפה גדולים יכולים לקדם את עולם ניהול ההשקעות ולשכלל שיטות קיימות.
אם יש לכם ניסיון בסיסי בתכנות תוכלו לפתוח סביבת עבודה בענן (קישור בראש העמוד) עם גוגל Colab ולהתנסות בקוד שכתבתי שמבצע את התהליך על דאטא סט של 18,755 תמלולים של שיחות משקיעים של כ-2900 חברות שונות שנערכו בין הרבעון השלישי של 2017 לרבעון השלישי של 2024. התהליך הזה דורש המון משאבי עיבוד (GPU) ולכן יישמתי כך שירוץ על תמלול בודד ולא על כל התמלולים.בהמשך ישיר, ממליץ בחום להשתמש באפשרות של Colab להחליף לסביבה עם GPU. לגבי המודל, במבחן שביצעו החוקרים הם השתמשו ב llama 3.1 8b של מטא (זמין דרך hugging face בהרשמה); אם אין לכן חשבון בhugging face תוכלו להתנסות בקוד עם מודל phi2 של מיקרוסופט אבל התשובות יהיו פחות איכותיות.
הערה טכנית אחרונה: התמלולים כולם נאספו מאתר Motley Fool ופורסמו בKaggle; אפתח פה סוגריים ואציין שמבדיקה שערכתי מצאתי אתרים שמספקים תמלולים שמכילים לא מעט טעויות תמלול שכמובן יפגעו באיכות התוצאה ולכן מגיע ח״ח ל-Motley Fool שמשתמשים במודל התמלול של Verbit הישראלית שמביאה תוצאת תמלול פנומנלית.
באופן אישי אני מעדיף להבין מלמעלה למטה (Top-down) אז נתחיל בסקירה של החלקים המרכזיים בתהליך ומשם נצלול להבנה של הנושאים המעניינים. את התהליך כולו אפשר לחלק לחמשת ראשי הפרקים הבאים כפי שחילקתי בקוד:
שאלה מאוד אינטואיטיבית בהקשר של מודלי שפה היא איך בכלל מחשב מבין תוכן של משפט או תמונה. בשורש היכולת הזו חבויה שיטת ההטמעה וקטורית שבעזרתה ממירים אובייקטים (מילים, משפטים, תמונות או אפילו משתמשים) לוקטורים במרחב רב מימדי (יכול להיות 100 או 300 ויותר מימדים), כלומר סדרת מספרים, בדרך כזו שהאובייקטים הדומים יותר יהיו קרובים יותר זה לזה במרחב הווקטורי. במילים פשוטות, הכוונה היא לייצוג של אובייקטים במרחב מספרי, שבו כל אובייקט מקבל ייצוג כמערך (או וקטור) של מספרים. את המערכים הללו אפשר להשוות, למיין, ולבצע עליהם חישובים נוספים.
את ההמרה הזו עושים באמצעות רשתות נוירונים (Neural Netowrks) שלומדות על בסיס המון דוגמאות של מידע לדייק את המערך הוקטורי שמייצג כל אובייקט. הוקטורים האלה הם הבסיס של הרבה מאוד יכולות בינה מלאכתותית כמו ניתוח שפה, חיפוש מבוסס משמעות (ולא רק מילים), זיהוי דמיון בין אוביקטים, סיפוק המלצות ועוד.
כדי לא להשאיר אף קורא מאחור, רשתות נוירוניות (ר״נ) הן למעשה הלחם והחמאה של התחום שנקרא למידה עמוקה (Deep Learning). ר״נ זה למעשה שם מפואר לאלגוריתם שמכיל שרשרת (או רשת) של פונקציות, ברובן לא לינאריות. להבדיל מהפונקציות שהכרנו בשיעורי חדו״א, אוסף כזה של פונקציות הוא בלתי פתיר בשיטות פורמליות ולכן הייחוד של האלגוריתם הזה טמונה ביכולת לבצע התאמה של הפרמטרים בכל פונקציה בשרשרת (המשקולות והקבועים) כדי להגיע לתוצאה אופטימלית בהתאם לפונקצית הפסד או עלות (Loss / Cost function). תהליך האופטימזציה נקרא אימון ובמהלכו מנסים באופן אקראי צמדים של קלט (תמונות, משפטים, סדרות זמן) ופלט (וקטור מוטמע, סיווג, סיגנל פיננסי וכו׳). לרוב בין שכבת הקלט, השכבה הראשונה בשרשרת הפונקציות, ושכבת הפלט יש מספר ״שכבות נסתרות״ (hidden layers) כלומר פונקציות ביניים ומכאן השם ״למידה עמוקה״.
בחזרה למאמר של S&P, במותודולוגיה שהוצגה כל משפט בדברי הפתיח, בשאלות המתומצתות, ובכל אחת מהתשובות עובד באמצעות הטמעה וקטורית ונשמר במאגר (דאטה בייס) ייעודי לוקטורים (בקוד שלי השתמשתי בFAISS של מטא). כדי לחשב את מידת ההתאמה הסמנטית בין צמד מסוים של שאלה ותשובה מבצעים חישוב Cosine Similarity בין כל משפט בשאלה וכל משפט בתשובה (מכפלה קרטזית של המשפטים) וע״מ לסכם לתוצאה אחת לכל צמד של שאלה ותשובה מחשבים ממוצעצ מהתוצאות של כל הקומבינציות.
Cosine Similarity הוא למעשה מדד לדמיון בין שני וקטורים במרחב שמתבסס על חישוב קוסינוס הזווית ביניהם. בפועל, אם שני וקטורים במרחב מצביעים לאותו הכיוון סימן שהדמיון ביניהם גבוה ולכן התוצאה תהיה קרובה ל 1 ולהבדיל אם הוקטורים הם בכיוון מנוגד סימן שהייצוג שלהם מנוגד והתוצאה תהיה קרובה ל 1-.
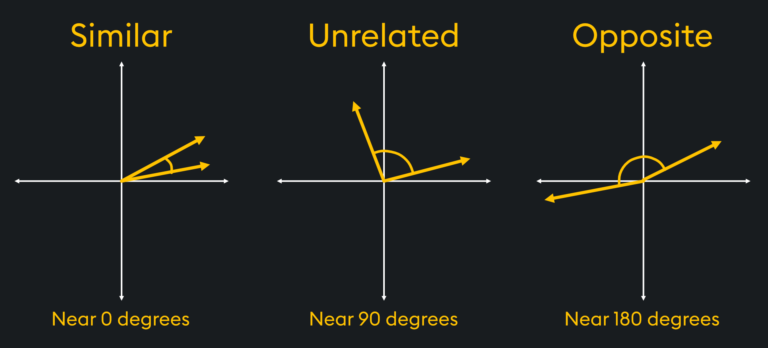
המחשה של Cosine Similarity במרחב דו מימדי. מקור: KDB.
כזכור, על מנת לאמוד את מידת הפרואקטיביות המאמר הציג פתרון יצירתי אינטילגנטי והוא שימוש במודל שפה כדי לייצר תשובה שמבוססת על דברי הפתיח והמידע שסיפקה ההנהלה בתשובות עד לאותה השאלה. בצורה הזו מסתנזים תשובה ברורה ותמציתית מכמה פיסות מידע שמפוזרות בנקודות שונות בשיחה, וכך מאפשרים השוואה יעילה אל מול השאלה.
כדי להבין את החשיבות של יצירה מבוססת אחזור בתחום הבינה מלאכותית יוצרת (GenAI) ניקח רגע צעד אחורה כדי להבין מה בעצם קורה מאחורי הקלעים. כדי ללמד את המחשב ליצור על בסיס נתונים חוקרי ה-AI בחרו להשתמש במודל הסתברותי. ההנחה היתה שאם המחשב ילמד את הסטטיסטיקה של המציאות, הוא יידע ליצור דברים שנראים כאילו הם מציאותיים גם אם הם לא. אבל המציאות היא לא רק הסתברותית אלא גם מוחלטת (דטרמיניסטית) וכשמשתמשים במודל הסתברותי כדי לחקות את המציאות, תמיד תהיה לו הסתברות ל"הזיות" (hallucinations). כך נוצרים איורי AI של ילד עם שלוש רגליים או טקסטים שמשרבבים שמות, מונחים או תקדימים משפטיים מומצאים - כולם תוצאה של דמיונו הפורה של הצ׳אט.
בעיית ההזיות היתה מוכרת לחוקרים בתחום מזה שנים רבות אך בשנתיים האחרונות רוכז המאמץ במציאת פתרונות הודות לזרקור החזק שהופנה לעבר הבעיה בזכות החשיפה הגבוהה של המודלים ויכולותיהם, לטוב ולרע, שהביא ChatGPT. אחת הגישות המובילות לפתרון של בעיית ההזיות נקרא grounding (מעניין באיזה מונח תבחר האקדמיה ללשון) והרעיון שלו הוא להשתמש במודל כדי לחפש (לאחזר) מידע מתוך מקורות מהימנים ואחר-כך לסנתז תשובה מקיפה מתוך התוצאות המובילות בעזרת יכולות העיבוד שפה. ככה למעשה מונעים מהמודל ״לזייף״ מציאות סבירה סטטיסטית ומשיגים את הטוב שבשני העולמות - גם מהיכולת ליצור תוכן מותאם וגם מהיכולת לחפש מידע רלוונטי על בסיס משמעות (ולא רק התאמה בין המילים).

תרשים של החלקים והתהליכים ביצירת תוכן בגישת RAG. מקור: AWS Documentation.
הדרך הכי פשוטה להבין איך שינוי בפרמטר הטמפרטורה משפיע על תוצאות מודל שפה היא פשוט לשאול את ֿChatGPT או כמעט כל מודל אחר את אותה שאלה מספר פעמים ולהוסיף ״תענה בטמפרטורה X" כאשר X הוא מספר בין 0 ל1. מה זה עושה? כשאנחנו מתמשים במודל שפה ליצירה, המודל מרכיב משפטים דרך השלמה של הרצף הטקסטואלי ע״י בחירת המילה (נקרא טוקן - Token) בעלת ההסתברות הגבוהה ביותר להתאמה סמנטית ותוכנית לחלק הבא ברצף. טמפרטורה נמוכה תביא לכך שהתוצאה שנקבל תהיה מורכבת מהמילים בעלות ההסתברות המקסימלית להתאמה בכל חלק וככה בעצם נלך על בטוח ונקבל תשובה ״קרה״. להבדיל, טמפרטורה גבוהה תיתן למודל חופש מסוים לבחור מילים פחות צפויות ולתת תשובות יותר מקוריות.
במקרה שימוש כמו זה שבמאמר כמובן שנעדיף טמרטורה נמוכה. גם לשאילתה (הפרומפט) בה השתמשו החוקרים (במסגרת מטה) יש תרומה חשובה לכיוונון המודל ולאופי התוצאות ובהקשר הזה כדי לשים לב ל-Knowledge cutoff שהוא פיצ׳ר של מודלי שפה מסוימים שמאפשר לייצר תוצאה על בסיס המידע שהיה קיים עד לאותו תאריך, כלומר להתעלם ממידע שנכלל בשלב האימון של המודל ונוצר לאחר התאריך הקובע, ובכך למנוע את הטיית החוכמה שבדיעבד (Hindsight bias) שהיתה מוכרת לאנשים בעולם השקעות עוד הרבה לפני עידן הבינה מלאכותית.
From the perspective of a top executive, please answer the following
question raised by a financial analyst during an earnings conference
call. Knowledge cutoff: {Date of the Earnings Call}.
הפריצה של ChatGPT גרמה לרבים לתלות תקוות גדולות ביכולת שלו, ישר מהמדף, לפצח את האניגמה שנקראת שוק ההון ולתת המלצות שיניבו תשואות גבוהות. כתבתי פה בעבר על הסיכון שבהישענות על קופסאות שחורות שכאלו, שלא מאפשרות בחינה וביקורת מקצועית של מומחה אנושי. המאמר הזה הוא דוגמה פנטסטית לפוטנציאל שיש במודלים האלו וממחיש את השינוי הטקטוני שמתחולל בעולם ההשקעות בדמות הסימביוזה בין מדעני הנתונים לבין אנליסטים פיננסים.
לעניות דעתי ההתקדמות בתחום ה-AI ומודלי שפה תביא בשנים הקרובות להתחזקות של שתי מגמות עיקריות: הראשונה היא מעבר מקרנות מחקות שעוקבות אחרי מדד משוקלל שווי שוק (Cap Weighted) לקרנות בטא חכמה. כתבתי בעבר על בעיית הריכוזיות שיוצרות הקרנות המחקות והקשר שלה לעולם תורת המשחקים. קרנות בטא חכמה עוקבות אחרי מדדים שמאגדים כמה פקטורים, כמו אלו שהוצגו במאמר, כדי לפזר את ההון על פני מדד מסוים (לדוגמה סקטוריאלי או גיאוגרפי) בצורה שמייצרת תשואה עודפת על המדד ה״טיפש״.
מגמה שנייה שלהערכתי תתחזק היא החיבור הישיר (Disintermediation) בין משקיעים וצרכני הון. הגל הקודם של התפתחות במודלים של ML הביא לצמיחה משמעותית בהיקף האשראי הצרכני שהוסט לפלטפורמות הלוואות חברתיות (P2P Lending) שהצליחו לייעל ולדייק את תהליך החיתום ואיפשרו לקרנות ומשקיעים פרטיים להיכנס בנעלי הבנקים וגופי המימון המסורתיים. החיבור הזה היה מתבקש וטבעי בזכות שפע המידע המובנה (Structured data) על היסטוריית האשראי של לווים והיכולת של המודלים מ׳הדור הראשון׳ לייצר תחזיות על בסיסו.
אם קראתם עד כאן אז קודם כל תודה! אני גם אשמח לקבל הערות ו/או הארות שיש לכם גם כדי להבין אם יש עניין בתוכן שלי בעברית.